Analysis
By tracking participants through up to five games of five rounds each, the PhotoBook dataset allows for investigating both in-game and inter-game effects. An in-depth analysis of both of these dimensions can be found in chapter 5 of Janosch Haber's Master's ThesisJanosch Haber.Here we will focus on the analysis of participants’ interaction during a game of five labelling rounds as reported in
How should we call it? - Introducing the PhotoBook Conversation Task and Dataset
for Training Natural Referring Expression Generation in Artificial Dialogue Agents.
Master’s Thesis. University of Amsterdam. Amsterdam, The Netherlands, 2018
Janosch Haber, Tim Baumgärtner, Ece Takmaz, Lieke Gelderloos, Elia Bruni, and Raquel Fernández.The data collected in the PhotoBook dataset largely confirms observations concerning participants’ task efficiency and language use during a multi-round communication task made by seminal, small-scale experiments such as those by Krauss and Weinheimer (1964); Clark and Wilkes-Gibbs (1986); Brennan and Clark (1996) and, due to its scale, offers additional aspects for further investigation.
The PhotoBook Dataset: Building Common Ground through Visually Grounded Dialogue.
In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), 2019
Task Efficiency
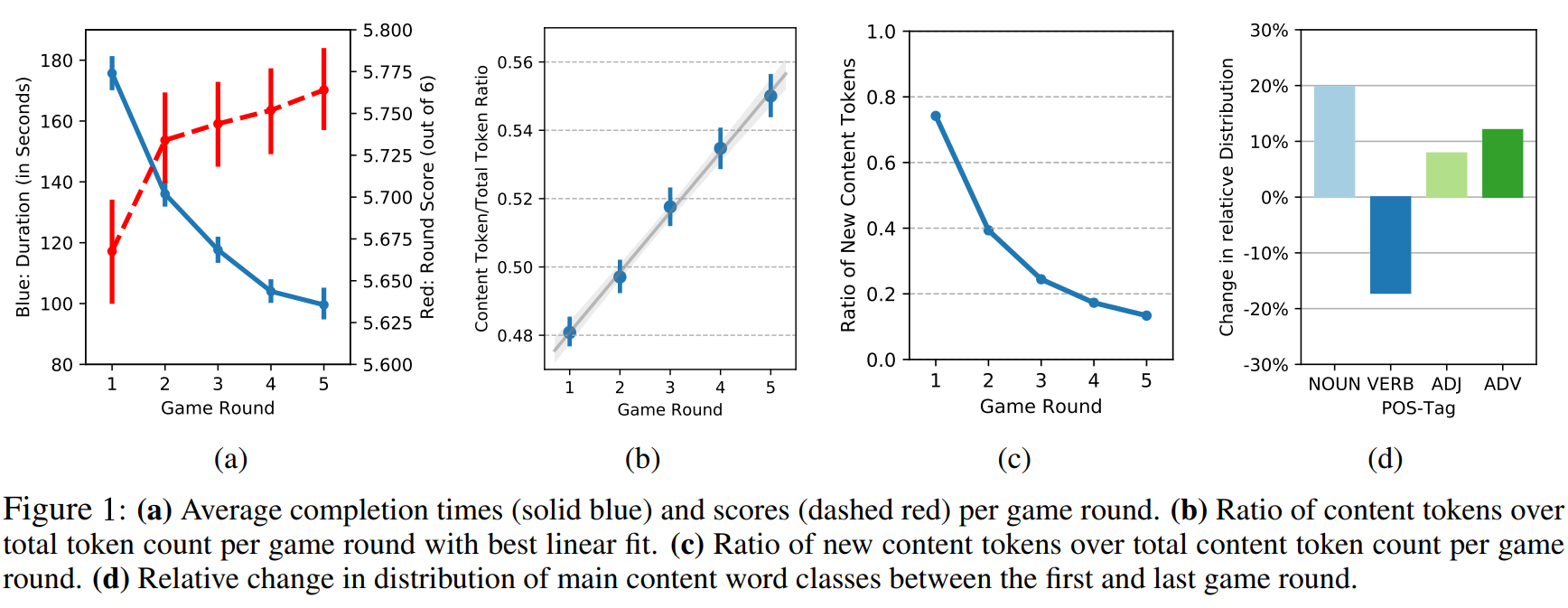 Completing the first round of the PhotoBook task
takes participants an average of almost three minutes. Completing the fifth round on the other hand
takes them about half that time. As Figure 1a
shows, this decline roughly follows a negative logarithmic function, with significant differences between rounds 1, 2, 3 and 4, and plateauing towards
the last round. The number of messages sent by
participants as well as the average message length
follow a similar pattern, significantly decreasing
between consecutive game rounds. The average
number of correct image labels, on the other hand,
significantly increases between the first and last
round of the game (cf. the red dashed graph in Figure 1a). As a result, task efficiency as calculated
by points per minute significantly increases with
each game round.
Completing the first round of the PhotoBook task
takes participants an average of almost three minutes. Completing the fifth round on the other hand
takes them about half that time. As Figure 1a
shows, this decline roughly follows a negative logarithmic function, with significant differences between rounds 1, 2, 3 and 4, and plateauing towards
the last round. The number of messages sent by
participants as well as the average message length
follow a similar pattern, significantly decreasing
between consecutive game rounds. The average
number of correct image labels, on the other hand,
significantly increases between the first and last
round of the game (cf. the red dashed graph in Figure 1a). As a result, task efficiency as calculated
by points per minute significantly increases with
each game round. Linguistic Properties of Utterances
To get a better understanding of how participants increase task efficiency and shorten their utterances, we analyse how the linguistic characteristics of messages change over a game. We calculated a normalised content word ratio by dividing the count of content words by the total token count. This results in an almost linear increase of content tokens over total token ratio throughout a game (average Pearson’s r per game of 0.34, p < 0.05, see Figure 1b).With referring expressions and messages in general getting shorter, content words thus appear to be favoured to remain. We also observe that participants reuse these content words. Figure 1c shows the number of novel content tokens per game round, which roughly follows a negative logarithmic function. This supports the hypothesis of participants establishing a conceptual pact on the referring expression attached to a specific referent: Once accepted, a referring expression is typically refined through shortening rather than by reformulating or adding novel information (cf., Brennan and Clark, 1996).
We also analysed in more detail the distribution of word classes per game round by tagging messages with the NLTK POS-Tagger. Figure 1d displays the relative changes in content-word-class usage between the first round and last round of a game. All content word classes but verbs show a relative increase in occurrence, most prominently nouns with a 20% relative increase. The case of adverbs, which show a 12% relative increase, is particular: Manual examination showed that most adverbs are not used to described images but rather to flag that a given image has already appeared before or to confirm/reject (‘again’ and ‘too’ make up 21% of all adverb occurrences; about 36% are ‘not’, ‘n’t’ and ‘yes’).
These results indicate that interlocutors are most likely to retain the nouns and adjectives of a developing referring expression, while increasingly dropping verbs, as well as prepositions and determiners. A special role here takes definite determiner ‘the’, which, in spite of the stark decline of determiners in general, increases by 13% in absolute occurrence counts between the first and last round of a game, suggesting a shift towards known information.
Finally, in contrast to current visual dialogue datasets (Das et al., 2017; De Vries et al., 2017) which exclusively contain sequences of questionanswer pairs, the PhotoBook dataset includes diverse dialogue acts. Qualitative examination shows that, not surprisingly, a large proportion of messages include an image description. These descriptions however are interleaved with clarification questions, acceptances/rejections, and acknowledgements.
The analysis presented here can be replicated with the
ACL_Analysis.ipynb Jupyter Notebook available in here in the download section. To run the script, place it in the same folder as the logs folder and the Out-of-Vocabulary Dictionary oov_dictionary.pickle and excecute the notebook.
References
- Susan E. Brennan and Herbert H. Clark. 1996. Conceptual pacts and lexical choice in conversation. Journal of Experimental Psychology: Learning, Memory, and Cognition, 22:1482–1493.
- Herbert H. Clark. 1996. Using Language. ’Using’ Linguistic Books. Cambridge University Press.
- Herbert H. Clark and Deanna Wilkes-Gibbs. 1986. Referring as a collaborative process. Cognition, 22(1):1 – 39.
- Abhishek Das, Satwik Kottur, Khushi Gupta, Avi Singh, Deshraj Yadav, Jose M.F. Moura, Devi ´ Parikh, and Dhruv Batra. 2017. Visual Dialog. In Proceedings of CVPR.
- Harm De Vries, Florian Strub, Jermie Mary, Hugo Larochelle, Olivier Pietquin, and Aaron Courville. 2017b. Modulating early visual processing by language. In Proceedings of NIPS
- Robert M. Krauss and Sidney Weinheimer. 1964. Changes in reference phrases as a function of frequency of usage in social interaction: a preliminary study. Psychonomic Science, 1(1):113–114.