The PhotoBook Dataset
Dialogue Samples
Dataset Architecture
Dataset Processor
Visualisation
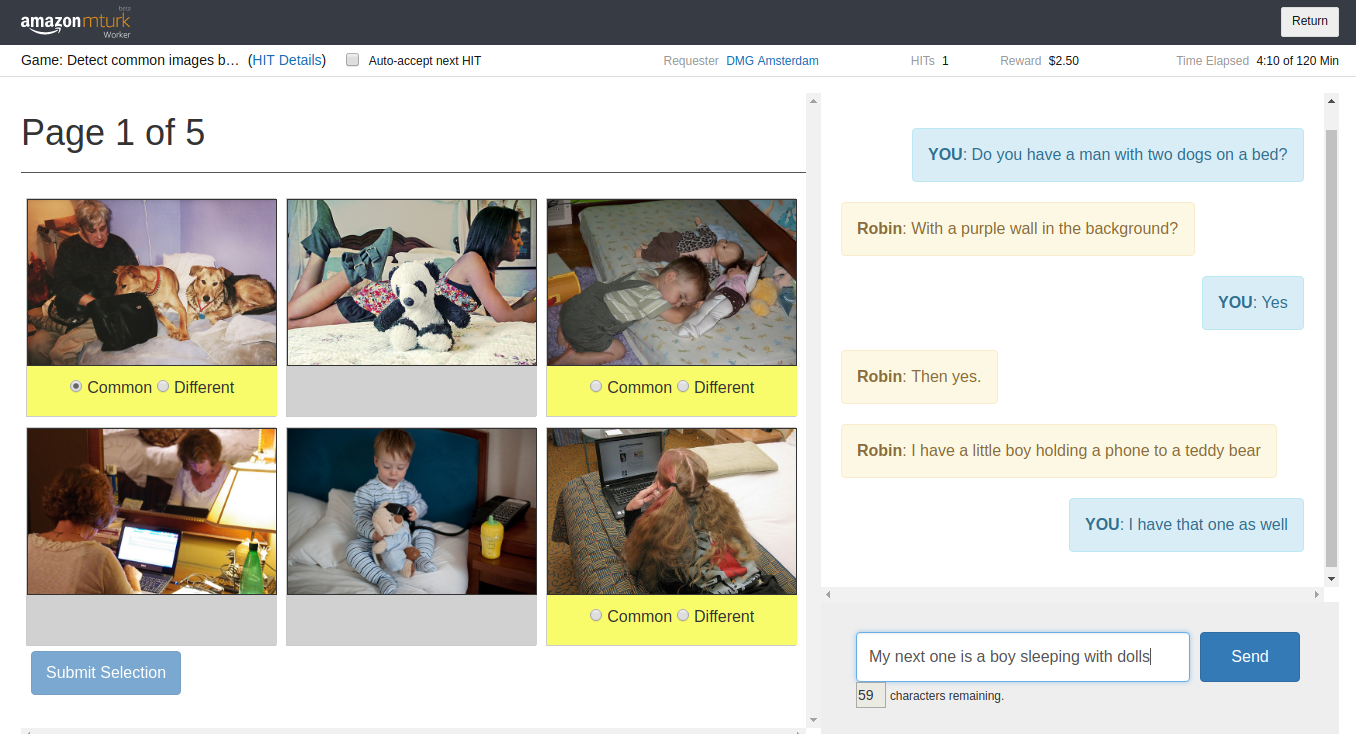
Dialogue Samples
Through the goal-oriented nature of participants' interactions in the PhotoBook dataset, we do not only collect image descriptions but rather the full,
collaborative process of establishing, grounding and refining referring expressions throughout the subsequent rounds of the PhotoBook task. As a result, we capture a wide range of
dialogue acts such as clarification questions, corrections, extensions, (self-)repairs as well as interactions concerning game mechanics. Consider for example the following interactions:
A: Man with dog on lap looking at his computer?
B: I don't have that, but could it be a TV in yours? Mine has a man sitting with his dog watching TV.
A: yes, TV - sorry!
B: Okay.
A: Do you have someone on a big motorcycle and their head isn't visible?
A: There is a blue car in the background
B: No
A: In any of the pictures?
B: No
A: Okay, thank you
B: Woman with hot dog
A: Older girl with glasses holding a hot dog?
B: sitting
A: Yeah
A: Do you have a picture with a lady in a fancy dress standing by a motorcycle?
B: no
B: wait
B: yes, in black?
A: Yes, it's a black dress with white trim.
A: Is there anything else?
B: Do you have the old lady in the white hat/blue pants reading?
A: Yes, I do.
B: Okay, that's all for me
In most cases, referring expressions agreed upon during the first rounds of a game are further refined and optimised while re-referring to the same target object in later rounds of the game. These
refinements often are manifested in an omission of detail while retaining core features of the target object.
A: Do you have a boy with a teal coloured shirt with yellow holding a bear with a red shirt?
B: Yes
-
B: Boy with teal shirt and bear with red shirt?
A: Yes!
-
A: Teal shirt boy?
B: No
Collecting all utterances that refer to a specific target image during a given game creates its co-reference chain. Consider the following examples of first and last references from co-reference chains manually extracted from the PhotoBook dataset:
F: Two girls near TV playing wii. One in white shirt, one in grey
L: Girls in white and grey
F: A person that looks like a monk sitting on a bench. He's wearing a blue and white ball cap
L: The monk
F: A white, yellow, and blue bus being towed by a blue tow truck
L: Yellow/white bus being towed by blue
A sample of full game of five rounds of participant interactions can be seen
here.
Dataset Architecture
The PhotoBook Dataset contains 2502 complete dialogues collected through the PhotoBook Conversation task. The dataset is anonymized but allows for tracking specific users over multiple games through a unique agent ID.
The raw PhotoBook Dataset is a collection of JSON files with three levels of data, pertaining either to the
Game, one of the five
Game Rounds or one of the variable number of
Messages in a game round. The data is structured as follows:
Dataset Architecture
The PhotoBook Dataset contains 2502 complete dialogues collected through the PhotoBook Conversation task. The dataset is anonymized but allows for tracking specific users over multiple games through a unique agent ID.
The raw PhotoBook Dataset is a collection of JSON files with three levels of data, pertaining either to the
Game, one of the five
Game Rounds or one of the variable number of
Messages in a game round. The data is structured as follows:
Top level: Game Data
| Key |
Value |
| "game_id" |
Unique game ID increasing relative to the game's initial timestamp. Integer ranging from 0 to 2501 |
| "domain_id" |
Indicates the image domain of the game. Integer ranging from 0 to 60. See details about the image domains here |
| "agent_ids" |
Ordered list of the unique agent IDs of the participants in this game; length = 2 |
| "agent_labels" |
Ordered list of the agents’ speaker labels A or B; length = 2 |
| "start_time" |
Timestamp of the conversation start. Format: YYYY-MM-DDTHH:mm:ss.ffffff |
| "feedback" |
Dictionary with the participant's feedback at the end of the game. Keys are the speaker labels A and B, values are pre-formated Strings. See their format here. Values are null if no feedback was given. |
| "rounds" |
Ordered list of Game Round Data objects; length = 5 |
2nd level: Game Round Data
| Key |
Value |
| "round_nr" |
Round number indicator. Integer ranging from 1 to 5 |
| "score" |
Dictionary of the participant's scores in this round. Keys are the speaker labels A and B, values are their integer points ranging from 0 to 3 |
| "images" |
Dictionary of the images displayed to the participant's in this round. Keys are the speaker labels A and B, values are the image paths relative to the images folder. |
| "common" |
Variable length list of the common images in this game round. Image paths are relative to the images folder. |
| "highlighted" |
Dictionary indicating whether the images displayed to the participant's were highlighted or not in this round. Keys are the speaker labels A and B, values are booleans indicating wheter the corresponding image was highlighted. |
| "messages" |
Ordered list of Message Data objects; variable length |
3rd level: Message Data
| Key |
Value |
| "timestamp" |
Message timestamp relative to the conversation start; HH:MM:SS[.ssssss] format |
| "turn" |
Turn indicator with respect to the current game round. A turn contains all subsequent utterances of an agent until the next utterance of the other agent |
| "speaker" |
Speaker label A or B of the current speaker |
| "agent_id" |
Agent ID of the current speaker |
| "message" |
Sent message. String. Game mechanic messages are indicated by an inital keyword in tag brackets. See here for a full list of tags. |
A
sample logfile can be seen
here.
Dataset Processor
To simplify processing, we provide a Python dataset processor that reads in the raw logfiles and creates
Log objects that contain the raw logfile data plus some additional fields.
The processor can be included into a Python project by adding
from processor import Logand accessed through the examplary code in the following snippet.
def load_logs(log_repository, data_path):
filepath = os.path.join(data_path, log_repository)
print("Loading logs from {}...".format(filepath))
missing_counter = 0
file_count = 0
for _, _, files in os.walk(filepath):
file_count += len(files)
print("{} files found.".format(file_count))
logs = []
for root, dirs, files in os.walk(filepath):
for file in files:
if file.endswith(".json"):
with open(os.path.join(root, file), 'r') as logfile:
log = Log(json.load(logfile))
if log.complete:
logs.append(log)
print("DONE. Loaded {} completed game logs.".format(len(logs)))
return logs
Then specify the relative path to the log folder and call the
load_logs function:
data_path = ""
logs = load_logs("logs", data_path)
The processor creates a list of
Log objects that hold the same three-tier structure of game, round and message data as described above, but hold some additional information and provide access through dot functions like
log.game_id. The information contained in a Log object is as follows:
Top level: Game Data
| Key |
Value |
| "game_id" |
Unique game ID increasing relative to the game's initial timestamp. Integer ranging from 0 to 2501 |
| "domain_id" |
Indicates the image domain of the game. Integer ranging from 0 to 60. See details about the image domains here |
| "domains"
|
List of the object types of the two main objects in the game's image set (i.e. its domain). List of Strings, length = 2
|
| "agent_ids" |
Ordered list of the unique agent IDs of the participants in this game; length = 2 |
| "agent_labels" |
Ordered list of the agents’ speaker labels A or B; length = 2 |
| "start_time" |
Timestamp of the conversation start. Format: YYYY-MM-DDTHH:mm:ss.ffffff |
| "duration"
|
Total duration of the game. Format: [H]H:MM:SS.ffffff
|
| "total_score" |
The participants total score obtained in the game. Integer ranging from 0 to 30
|
|
"scores"
|
Dictionary of participants' total game scores. Keys are the speaker labels A and B, values are their integer points ranging from 0 to 15
|
| "feedback" |
Dictionary with the participant's feedback at the end of the game. Keys are the speaker labels A and B, values are pre-formated Strings. See their format here. Values are null if no feedback was given. |
| "rounds" |
Ordered list of GameRound objects; length = 5 |
2nd level: Game Round Data
| Key |
Value |
| "round_nr" |
Round number indicator. Integer ranging from 1 to 5 |
| "duration"
|
Total duration of the game round. Format: [H]H:MM:SS.ffffff
|
| "total_score" |
The participants total score obtained in the game round. Integer ranging from 0 to 6
|
| "scores" |
Dictionary of the participant's scores in this round. Keys are the speaker labels A and B, values are their integer points ranging from 0 to 3 |
| "num_messages |
Total number of messages sent in this game round. Integer |
| "images" |
Dictionary of the images displayed to the participant's in this round. Keys are the speaker labels A and B, values are the image paths relative to the images folder. |
| "common" |
Variable length list of the common images in this game round. Image paths are relative to the images folder. |
| "highlighted" |
Dictionary indicating whether the images displayed to the participant's were highlighted or not in this round. Keys are the speaker labels A and B, values are booleans indicating wheter the corresponding image was highlighted. |
| "messages" |
Ordered list of Message objects; variable length |
3rd level: Message Data
| Key |
Value |
| "message_id" |
Message index, starting with the first message in the game. Integer |
| "timestamp" |
Message timestamp relative to the conversation start; HH:MM:SS[.ssssss] format |
| "turn" |
Turn indicator with respect to the current game round. A turn contains all subsequent utterances of an agent until the next utterance of the other agent |
| "speaker" |
Speaker label A or B of the current speaker |
| "agent_id" |
Agent ID of the current speaker |
| "message" |
Sent message. String. Game mechanic messages are indicated by an inital keyword in tag brackets. See here for a full list of tags. |
Visualisation
The following snippet will print a game transcript as shown
here:
def print_transcript(log):
print("Game ID: {}".format(log.game_id))
print("Domain ID: {}".format(log.domain_id))
print("Image set main objects: '{}' and '{}'".format(log.domains[0], log.domains[1]))
print("Participant IDs: {} and {}".format(log.agent_ids[0], log.agent_ids[1]))
print("Start Time: {}".format(log.start_time))
print("Duration: {}".format(log.duration))
print("Total Score: {}".format(log.total_score))
print("Player scores: A - {}, B - {}".format(log.scores["A"], log.scores["B"]))
print("Transcript:\n")
for round_data in log.rounds:
print("Round {}".format(round_data.round_nr))
for message in round_data.messages:
if message.type == "text":
print("[{}] {}: {}".format(Log.format_time(message.timestamp), message.speaker, message.text))
if message.type == "selection":
label = "common" if message.text.split()[1] == "" else "different"
print("[{}] {} marks image {} as {}".format(Log.format_time(message.timestamp), message.speaker, Log.strip_image_id(message.text.split()[2]), label))
print("\nDuration: {}".format(round_data.duration))
print("Total Score: {}".format(round_data.total_score))
print("Player scores: A - {}, B - {}".format(round_data.scores["A"], round_data.scores["B"]))
print("Number of messages: {}\n".format(round_data.num_messages))
A similar tool to create HTML visualisations of the games including the displayed sets of images will be made available soon.